Why you should learn Git
![]()
How many times have you been working on a program, found a solution to a problem, implement it and later try to implement a better solution for the very same problem? How many times have you finished messing it up and having to Cmd-Z’d (Ctrl-Z’d for the non-Mac friends) dozens of times to reach the same point you were an hour ago? This happens to me a lot of times. And not only this problem, I usually have other problems that Git solves for me.
Advantages for groups
Synchronizing changes
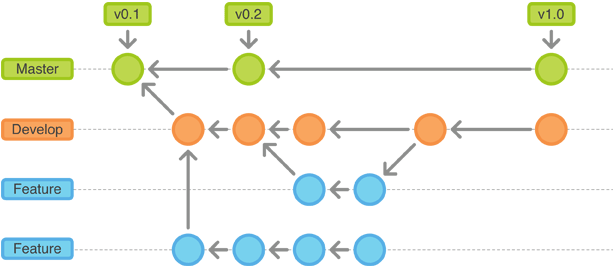 As a college student I’ve to work in small groups for small projects. These projects usually are coordinated via Dropbox, or warning our teammates with a text-message or an email before changing anything. That’s not the best approach but it works when you see your co-workers almost 5 days a week and you are the only one that modifies the large majority of files. But this is not the general scenario.
As a college student I’ve to work in small groups for small projects. These projects usually are coordinated via Dropbox, or warning our teammates with a text-message or an email before changing anything. That’s not the best approach but it works when you see your co-workers almost 5 days a week and you are the only one that modifies the large majority of files. But this is not the general scenario.
Coordinating changes “manually” has a lot of drawbacks. If your files are not automatically synchronized, you have to check which files have been modified and which are those modifications, and then apply them to your code. If modifications are not commented you don’t even know why have been made and what to expect when you run the program. «It worked before but it doesn’t now, is it my fault, is it intended or is it my teammate’s fault?».
If your files are automatically updated (see Dropbox) it could be even worse. Let’s think about this scenario. You (A) and your mate (B) are working on file F. At time 0 you start working on F. At time 1 your mate starts working with F. At time 2 you save the file. At time 3 your mate saves the file. Which version of the file must be stored? Your version? Your mate’s? Dropbox solves this creating a “Conflicted copy”: a duplicated of the file that can’t be automatically stored because the original version was modified after you opened it and before you saved it. But this can happen also in other situations, for instance, if you work without Dropbox application being executed, or without an Internet connection (more info).
This is a real case that happened to me: I was working on Front.me on July. I didn’t have Internet connection so I worked offline. I was working on my desktop but one day I decided to copy the project manually to the laptop, get it connected to the Internet and sync Dropbox folder. When I came back home at the end of the month and synced my desktop’s Dropbox folder I got a bunch of “Conflicted copy” files, because the version on Dropbox (at time 1) wasn’t the same that I used when started modifying the files (version at time 0) resulting in a “Conflicted copy” of all the files I had on my desktop computer (at time 2).
Git offers branches to separate the “working spaces” of each team member, as well as offers a merge tool to apply changes made to files of one branch to other one.
Who did what

When working in groups it is interesting to know who did what changes. Maybe someone didn’t understand well how to use a specific feature, or the opposite, maybe one is really good at one aspect and his code can be used as a good template for new additions. Keeping a record of who did what changes is really tedious on a non-version-controlled environment.
Advantages for individuals
Distributed system
Computers crash, disks get broken. Data is accidentally erased or gets corrupted. These are things that happen (sometimes) and that happen without warning you before they happen. You can’t trust your computer to be a safe place to store your critical project. You can’t also trust on a unknown central repository stored at an unknown datacenter. A single point of failure is not acceptable, a distributed alternative is the only valid approach.
Git is completely decentralized. That means that with any copy of your repository you can create a new one (clone). It doesn’t matter if the copy you’re cloning is a copy of the original repository, the original one, if it is stored on your local machine or on a remote computer… If you have a working copy of the repository you can rebuild all the other copies in a few minutes. If your disk gets broken but you have a copy of the repository on a flash drive, you can clone it to your computer and continue working.
Another real-life story: last month I was using a flash drive to store the Git repository used as “central repository”. One day there was a power failure and data on the drive got corrupted. The drive itself was broken and each time I disconnected it from the computer the data got lost. Luckily I had my local version of the repository so I could clone it to a different drive and continue working without losing any change.
Revisions
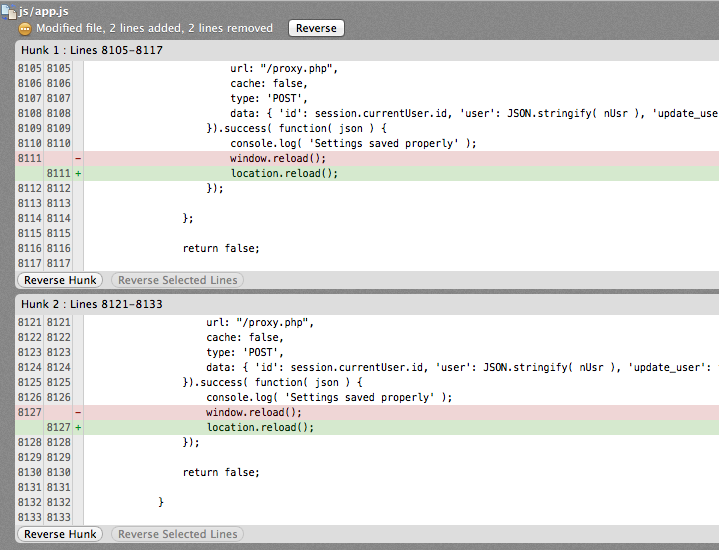
Git keeps a track of all the changes you make to your files. You can add more “breakpoints” (commits) or less, but you can compare each pair of commits and see what changes you made. As all the changes are stored on all the copies of the repository, you can check all the commits no matter on what machine were made as far as both repositories are up to date.
You can also see when you added a file to the project (or removed it) or even when a file was renamed. Of course, you can ignore some files and prevent tracking them and storing them on the repository.
Fast. Fast, fast. Fast!
With Git you work with a complete copy of the repository on your local machine, so almost all the operations are instantaneous. Changing the active branch, comparing two commits, getting a copy of a file of a specific commit…
Where to learn
If you want to learn more about Git I suggest you Pro Git book, available free online and a printed version on Amazon.
No replies on “Why you should learn Git”