This post was published 11 years ago so it may be outdated.
How many times have you been working on a program, found a solution to a problem, implement it and later try to implement a better solution for the very same problem? How many times have you finished messing it up and having to Cmd-Z’d (Ctrl-Z’d for the non-Mac friends) dozens of times to reach the same point you were an hour ago? This happens to me a lot of times. And not only this problem, I usually have other problems that Git solves for me.
Advantages for groups
Synchronizing changes
As a college student I’ve to work in small groups for small projects. These projects usually are coordinated via Dropbox, or warning our teammates with a text-message or an email before changing anything. That’s not the best approach but it works when you see your co-workers almost 5 days a week and you are the only one that modifies the large majority of files. But this is not the general scenario.
Coordinating changes “manually” has a lot of drawbacks. If your files are not automatically synchronized, you have to check which files have been modified and which are those modifications, and then apply them to your code. If modifications are not commented you don’t even know why have been made and what to expect when you run the program. «It worked before but it doesn’t now, is it my fault, is it intended or is it my teammate’s fault?».
If your files are automatically updated (see Dropbox) it could be even worse. Let’s think about this scenario. You (A) and your mate (B) are working on file F. At time 0 you start working on F. At time 1 your mate starts working with F. At time 2 you save the file. At time 3 your mate saves the file. Which version of the file must be stored? Your version? Your mate’s? Dropbox solves this creating a “Conflicted copy”: a duplicated of the file that can’t be automatically stored because the original version was modified after you opened it and before you saved it. But this can happen also in other situations, for instance, if you work without Dropbox application being executed, or without an Internet connection (more info).
This is a real case that happened to me: I was working on Front.me on July. I didn’t have Internet connection so I worked offline. I was working on my desktop but one day I decided to copy the project manually to the laptop, get it connected to the Internet and sync Dropbox folder. When I came back home at the end of the month and synced my desktop’s Dropbox folder I got a bunch of “Conflicted copy” files, because the version on Dropbox (at time 1) wasn’t the same that I used when started modifying the files (version at time 0) resulting in a “Conflicted copy” of all the files I had on my desktop computer (at time 2).
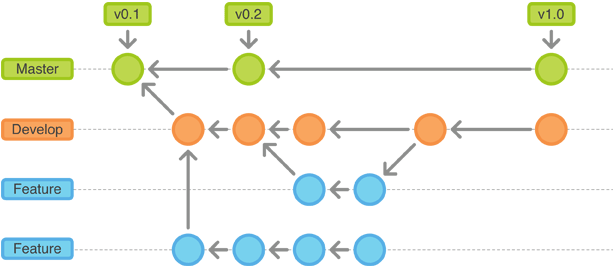
Git offers branches to separate the “working spaces” of each team member, as well as offers a merge tool to apply changes made to files of one branch to other one.
Who did what
One of my shared repositories
When working in groups it is interesting to know who did what changes. Maybe someone didn’t understand well how to use a specific feature, or the opposite, maybe one is really good at one aspect and his code can be used as a good template for new additions. Keeping a record of who did what changes is really tedious on a non-version-controlled environment.
Advantages for individuals
Distributed system
Computers crash, disks get broken. Data is accidentally erased or gets corrupted. These are things that happen (sometimes) and that happen without warning you before they happen. You can’t trust your computer to be a safe place to store your critical project. You can’t also trust on a unknown central repository stored at an unknown datacenter. A single point of failure is not acceptable, a distributed alternative is the only valid approach.
Git is completely decentralized. That means that with any copy of your repository you can create a new one (clone). It doesn’t matter if the copy you’re cloning is a copy of the original repository, the original one, if it is stored on your local machine or on a remote computer… If you have a working copy of the repository you can rebuild all the other copies in a few minutes. If your disk gets broken but you have a copy of the repository on a flash drive, you can clone it to your computer and continue working.
Another real-life story: last month I was using a flash drive to store the Git repository used as “central repository”. One day there was a power failure and data on the drive got corrupted. The drive itself was broken and each time I disconnected it from the computer the data got lost. Luckily I had my local version of the repository so I could clone it to a different drive and continue working without losing any change.
Revisions
Changes I made to a file
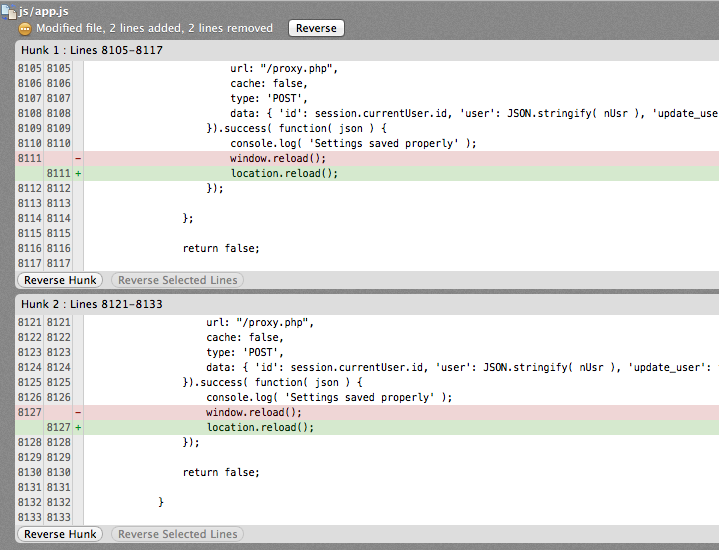
Git keeps a track of all the changes you make to your files. You can add more “breakpoints” (commits) or less, but you can compare each pair of commits and see what changes you made. As all the changes are stored on all the copies of the repository, you can check all the commits no matter on what machine were made as far as both repositories are up to date.
You can also see when you added a file to the project (or removed it) or even when a file was renamed. Of course, you can ignore some files and prevent tracking them and storing them on the repository.
Fast. Fast, fast. Fast!
With Git you work with a complete copy of the repository on your local machine, so almost all the operations are instantaneous. Changing the active branch, comparing two commits, getting a copy of a file of a specific commit…
This post was published 14 years ago so it may be outdated.
Vale, pensaba que no tendría tiempo y que tendría que retrasar la aplicación hasta verano, pero no, al final con un esfuerzo extra y un par de días de completa dedicación al proyecto, he podido acabar la aplicación hace apenas un semana (el resto del tiempo ha estado en revisión). Así que hoy toca presentación de la aplicación.
¿Qué es Music Maniac?
¿Recordáis el juego del concurso musical de los antiguos iPod Video? Para los que no os suene, se trataba de un juego muy sencillo en el que sonaba durante unos segundos una canción y se te ofrecían una serie de títulos entre los que elegir. Si acertabas el título conseguías puntos y si fallabas, no. Además, cuánto más rápido acertases más puntos ganabas, así que la velocidad era importante.
Music Maniac es mi idea de cómo debería haber sido ese juego llevada a iOS. ¿Y qué tiene de nuevo Music Maniac? Para empezar, más flexibilidad: se puede jugar con sólo los títulos de las canciones, con los nombres de los álbumes, con los nombres de los artistas, con las carátulas de los álbumes o con combinaciones de los anteriores. También se puede personalizar la duración de las canciones o el número de rondas.
Se puede jugar tanto con canciones de nuestra biblioteca de iTunes (a las que será necesario añadirle los datos del título, artista, álbum y carátula, ya que de algún sitio tiene que sacar la información sobre la canción Music Maniac) como con las canciones más populares de la iTunes Store. Sin embargo los modos de juego son diferentes: en el modo offline podemos jugar las rondas que queramos, hasta cansarnos o hasta fallar por primera vez, mientras que en el modo online sólo podemos jugar 10 rondas (esto es porque deben descargarse las canciones y el proceso requiere tanto tiempo para descargarlas como memoria libre para almacenarlas).
Como aliciente al modo offline, se puede jugar con amigos con un sólo dispositivo, pasándolo al terminar cada ronda y viendo después quién ha conseguido más puntos. Pero la competición no acaba en el modo offline, ya que Music Maniac tiene clasificaciones y logros de Game Center, con lo cual podrás ver quién conoce mejor su música y quién los éxitos de la iTunes Store. También podrás desbloquear logros acertando rondas en pocos segundos o acumulando cierta cantidad de puntos.
Music Maniac estará disponible en unas horas de forma gratuita en una versión Lite, en la que sólo se puede jugar en el modo offline, sin personalizar las rondas y sin enviar las puntuaciones a Game Center y en versión completa por 0.99$ (0.79€).
La aplicación es universal: está adaptada tanto a iPod Touch y iPhone (también a la Retina Display del iPhone 4) como a iPad. Además está traducida al inglés, catalán y español (lo siento, no hablo más idiomas, así que lo dejo en esos tres).
Próximas actualizaciones
Seguramente habréis visto por la App Store muchas aplicaciones que comienzan con una versión 1.0 y al cabo de un tiempo lanzan la versión 2.0 como aplicación independiente de la anterior. Esto no va a pasar con Music Maniac. Music Maniac sólo habrá una, se actualizará (sí, habrá versión 2.0, me gustaría desarrollarla en verano) y sus actualizaciones serán gratuitas para todo aquel que comprase la versión anterior y tendrá el mismo precio que la aplicación original para aquellos que no la comprasen.
También aviso que no habrá cambios de precio, ni subidas ni bajadas. La aplicación costará siempre 0.99$ (a no ser que Apple me impida ponerle ese precio), así que no os precupéis por posibles subidas de precio futuras: no las habrá.
This post was published 14 years ago so it may be outdated.
Vía Genbeta descubro que en las últimas Betas de Windows Live Messenger ya está disponible la compatibilidad del cliente de mensajería instantánea de Microsoft con el chat de Facebook. La pega es que de momento sólo está disponible para algunos paises, entre los cuales no está España, aunque es posible evitar la limitación cambiando la configuración de nuestra cuenta de Windows Live, indicando que residimos en Estados Unidos.
This post was published 14 years ago so it may be outdated.
Antes (izquierda) y después (derecha)
Cuando se lleva algún tiempo programando se acaban cogiendo manías y estilos a la hora de escribir el código, una de las más comunes es escribir las llaves ({ y }) en la línea siguiente, en lugar de en la línea en la que acaba la sentencia, manía que además suele considerarse como buena práctica.
[objc]
// Con las llaves en la misma línea
– (void)funcionDePrueba {
if (condicion) {
[self otraFuncion];
}
}
// Con las llaves en la línea siguiente
– (void)funcionDePrueba
{
if (condicion)
{
[self otraFuncion];
}
}
[/objc]
La cuestión es que ahora que estoy programando en Objective-C y utilizo Xcode, se me hace muy molesto que el autocompletado de código me añada las llaves en la misma línea que la sentencia, en lugar de la siguiente (cuando programo en PHP, el editor que uso no autocompleta el código). Sin embargo hay una forma sencilla de hacer que añada las llaves en la línea siguiente: tan sólo tenemos que escribir el siguiente código en la terminal y reiniciar Xcode.
This post was published 14 years ago so it may be outdated.
Vía AppleWeblog descubro que la última versión de la aplicación Camera+, una aplicación para el iPhone que permitía sacar fotos con más opciones que la aplicación que viene por defecto, fue rechazada por permitir habilitar la opción de usar los botones de control de volumen para capturar fotografías (función que había sido pedida en muchas ocasiones por los usuarios).
Lamentablemente la cosa no ha quedado así, y es que resulta que había un método oculto para activar esta función en versiones anteriores de la aplicación visitando desde safari la dirección camplus://enablevolumesnap, pudiendo desactivarla visitando camplus://disablevolumesnap; que parece que Apple ha descubierto recientemente, motivo por el cual han eliminado de la AppStore la aplicación, que reportaba cerca de 25000$ al mes a TapTapTap.
This post was published 14 years ago so it may be outdated.
Una de las cosas que se hacen molestas de tener varios equipos es que acabas diseminando los archivos que más usas entre ellos, de modo que en el sobremesa acabas teniendo archivos que no están en el portátil, y en el portátil acabas teniendo archivos que no están en el sobremesa. Para poder acceder a estos archivos acabas teniendo que crear una carpeta compartida en ambos equipos para ir actualizando los archivos que más sueles usar, utilizas un pendrive para trasportarlos, o acabas enviándote por emails los archivos cada vez que los modificas, sin embargo estas no son las opciones más cómodas.
Dropbox es un gran alternativa para este problema. Se trata de una aplicación que crea una carpeta en nuestro equipo que se sincroniza con una carpeta en un servidor remoto. Cada vez que añadimos algo en nuestra carpeta, se añade en la carpeta del servidor remoto, de modo que podemos acceder a los archivos de dicha carpeta desde cualquier ordenador conectado a Internet, a través de la web de Dropbox. También podemos instalar la aplicación en todos nuestros equipos, y al modificar un archivo de la carpeta de Dropbox en un equipo, se modifica en todos los demás equipos que tengan la aplicación instalada, sin necesidad de estar todos encendidos a la vez, ya que se sincronizan con el servidor remoto.
La aplicación es gratuita y está disponible tanto para Windows como para Mac OS X y Linux, además de móviles con Android, iPhone, iPad y próximamente Blackberry. Ofrece un espacio de 2GB de forma totalmente gratuita, aunque por 9.99$ al mes podemos ampliar este espacio a 50GB y por 19.99$ disponemos de 100GB. También podemos ampliar nuestro espacio disponible de forma gratuita invitando a nuestros amigos a Dropbox de modo que por cada amigo que se registre en Dropbox ampliaremos en 250MB la capacidad de nuestra cuenta, hasta llegar al límite de 8GB.
This post was published 14 years ago so it may be outdated.
Parece que Apple está interesada en que sus dispositivos con iOS (iPhone, iPod y iPad) tengan acceso a iBooks, una aplicación que nos permite gestionar y leer libros. Desde la versión 1.1 podemos leer PDF desde la misma aplicación, sin embargo hay ciertas opciones que no podemos configurar al leer PDF y sí al leer ePub, como el tamaño de la letra, lo que hace que leer, por ejemplo, el manual de usuario de iOS 4 sea realmente incómodo al tener que hacer zoom cada dos por tres.
Afortunadamente tenemos una alternativa: podemos convertir nuestros PDF en ePub. Hay muchas aplicaciones para hacer esto, tanto online como offline, pero en este artículo sólo me centraré en una aplicación. Calibre (así es como se llama la utilidad que nos permitirá convertir nuestros PDF en ePub) es totalmente gratutia y está disponible tanto para Windows como para Linux y Mac OS X. Read more →
This post was published 14 years ago so it may be outdated.
Vía Genbeta descubro que la fecha de lanzamiento de Microsoft Office 2011 para Mac es el día 2 de octubre de este año. Esta nueva versión se pondrá a la venta en dos paquetes distintos: Home and Student, que por 119$ incluye Word, Powerpoint, Excel y Messenger; y Home and Business, que con un precio de 199$ añade Outlook al paquete.
Además, aquellos que compren Microsoft Office 2008 para Mac antes del 30 de noviembre, podrán actualizarlo a esta versión de forma gratuita.
This post was published 15 years ago so it may be outdated.
En muchas ocasiones necesitamos comprar dos archivos de texto para ver qué diferencias hay entre ellos, como por ejemplo si queremos ver las diferencias entre dos versiones de un script PHP. Vale, cuando son scripts de un par de centenares de líneas no hay problema, pero, ¿qué me decís si queréis comparar dos archivos de varios miles (o decenas de miles) de líneas de código? Hacerlo “manualmente” no tiene sentido, y es aquí donde entra FileMerge.
Buscando FileMerge
FileMerge es una de las aplicaciones que vienen con el disco de instalación de Mac OS X, y se instala juntamente con Xcode y todo el entorno de desarrollo de Mac OS X, así que por defecto no la encontraréis instalado. Una vez tengáis instalado Xcode bastará con que busquéis con Spotlight “FileMerge” y lo ejecutéis.
Interfaz de FileMerge
La interfaz es muy intuitiva: se arrastra un archivo al recuadro de la izquierda y otro al recuadro de la derecha y a continuación se hace clic en “Compare”. Esperamos unos segundos (dependiendo de los archivos) a FileMerge acabe de encontrar las diferencias y finalmente veremos una ventana dividida en dos partes. Cada parte tiene el contenido de un archivo y las diferencias aparecen marcadas en ambos lados. También nos ofrece un recuento de diferencias.
Es realmente útil para comparar dos versiones diferentes de un archivo y ver qué cambios se han realizado de forma más cómoda y rápida. Se acabó el tener que ir línea a línea buscando diferencias, con FileMerge el trabajo se hace mucho más sencillo.
This post was published 15 years ago so it may be outdated.
Antes de nada, disculpad el retraso. Quería haber publicado este artículo anteayer o ayer, pero al final se me fueron juntando cosas y no ha sido posible. Pero como dice el refrán, más vale tarde que nunca, así que vamos allá.
En la keynote del lunes se presentó el nuevo iPhone 4, se dio un repaso al iPhone OS 4, iOS4 a partir de ahora y se mostró por primera vez iMovie para el iPhone. Además durante la sesión de “Safari, Internet adn Web State of the Union” se presentó Safari 5, que ya está disponible para Mac OS X y Windows. Por último, algunas operadoras han confirmado que la exclusividad del iPhone se ha acabado en España. Pero veamos de una en una las novedades.
 As a college student I’ve to work in small groups for small projects. These projects usually are coordinated via Dropbox, or warning our teammates with a text-message or an email before changing anything. That’s not the best approach but it works when you see your co-workers almost 5 days a week and you are the only one that modifies the large majority of files. But this is not the general scenario.
As a college student I’ve to work in small groups for small projects. These projects usually are coordinated via Dropbox, or warning our teammates with a text-message or an email before changing anything. That’s not the best approach but it works when you see your co-workers almost 5 days a week and you are the only one that modifies the large majority of files. But this is not the general scenario.